A client asked me what happens if ESXi servers are pointed towards the Windows domain name in “Time Configuration” and one or more domain controllers are not contactable. While I had a theory, I realised I have never tested what actually happens and what is the failure process. I have seen many environments where using the domain FQDN as the time source has become “de-facto” practice so I thought I should test the scenario and document the results.
Disclaimers:
- The tests were carried out in my home lab,
- ESXi clusters tested were running vSphere 5.1 and 5.5,
- There were only two DCs so I could only shutdown one, and
- It was a flat network with no firewalls between the machines.
Tests:
I configured the two clusters mentioned above to point towards my domain FQDN name and checked current time status on each ESXi host. I could see “dc2” being the configured time source and time was accurate. After that, I shutdown one of the domain controllers and started monitoring the ESXi hosts to see what happens.
The initial findings were:
- Pointing the ESXi hosts to domain name, will result in a round-robin resolution of the domain controllers to use for time. However, that will be “just the one time source” for it to use,
- Once it has resolved a name, it will use that domain controller for the time service, until there are 8 consecutive failures, and
- The polling interval starts with 64 seconds but gradually grows to 1024 seconds (just over 17 minutes).

You can see in the screenshot above that only one of my two domain controllers is in the configuration, which it kept trying to contact after it was taken down. This screenshot was taken after eight failed attempts. You can tell from the “reach” column which displays results of the last eight attempts in octal format. If all is good, this should show 377 but with more than 8 unsuccessful attempts, it has gone down to 0.
Now I was expecting that after 8 failures, the ESXi hosts will do another lookup. However, none of the ESXi hosts tried another lookup, on either cluster! Once I brought the shutdown DC back after over 5 hours, the ESXi hosts started synchronizing time with it automatically but only on the next polling period.
Analysis:
The test confirmed to me that having domain names in the configuration (instead of individual domain controller FQDNs or IP addresses) could result in a situation where the ESXi hosts may stop synchronizing their time, if they can’t connect to the looked-up DC and then won’t try another lookup, unless the service is restarted. Service restart might also be hit and miss, depending on what round-robin returns.
Another point to consider is that DNS will return all DCs that resolve to a domain name but not all of them may be available to an ESXi host, due to port blocks etc., which is quite common in larger environments. As far as the NTP client is concerned, it’s a valid result so it won’t try another lookup and may keep trying a domain controller it cannot connect to, resulting in eventual failure.
Needless to say, a shutdown domain controller (for maintenance etc.) will also cause the same issues.
As compared to that, having individual DC FQDNs/IPs in “Time Configuration” has the following benefits:
- One can point to specific DCs according to port access policies,
- As they’re individually mentioned, all of them are active at the same time, and
- Having a shutdown DC doesn’t have an impact as there are others to pick up the service.
Have a look at the screenshot below:

Here I had FQDN entries of the two domain controllers individually in the time configuration. Both DCs contribute to the service as a result and the configuration is already resilient because of that.
If the environment and access policies allows (e.g. in a lab), one can also point the service to VMware’s NTP aliases. Here is what happens when I point my cluster towards the following entries:
0.vmware.pool.ntp.org
1.vmware.pool.ntp.org
2.vmware.pool.ntp.org
3.vmware.pool.ntp.org
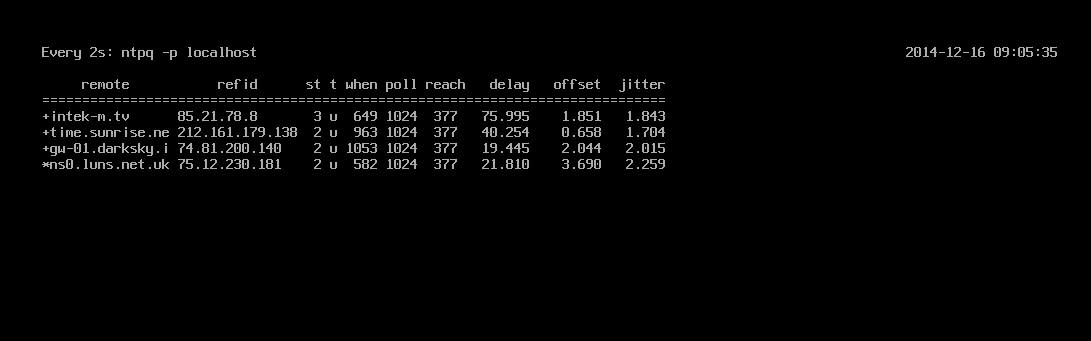
As you can see, four different entries resolve to four different external time servers to sync time with. Surely, this is more resilient, however, this might not be suited to all environments.
Conclusion:
This little but tedious experiment confirms what I’ve always thought: Time configuration on a vSphere environment should always be pointed towards individual FQDNs or IP addresses of reliable time sources and not towards a Windows domain FQDN. Doing so technically works and is easy to configure but does make your host time configuration unreliable, causing time drift situations.
[…] least one of them – if reasonable – in the same time zone as you. BTW, here is the article that got me started on this subject. I did not know that VMware had its own NTP pools. I often […]
[…] few months back, I used this command during an investigation into a NTP-related question from a customer. The command used in that case […]